AISB
AI Scientist Benchmark
Evaluating complete AI research capability: discover problems, form hypotheses, run real experiments, and write traceable research papers.
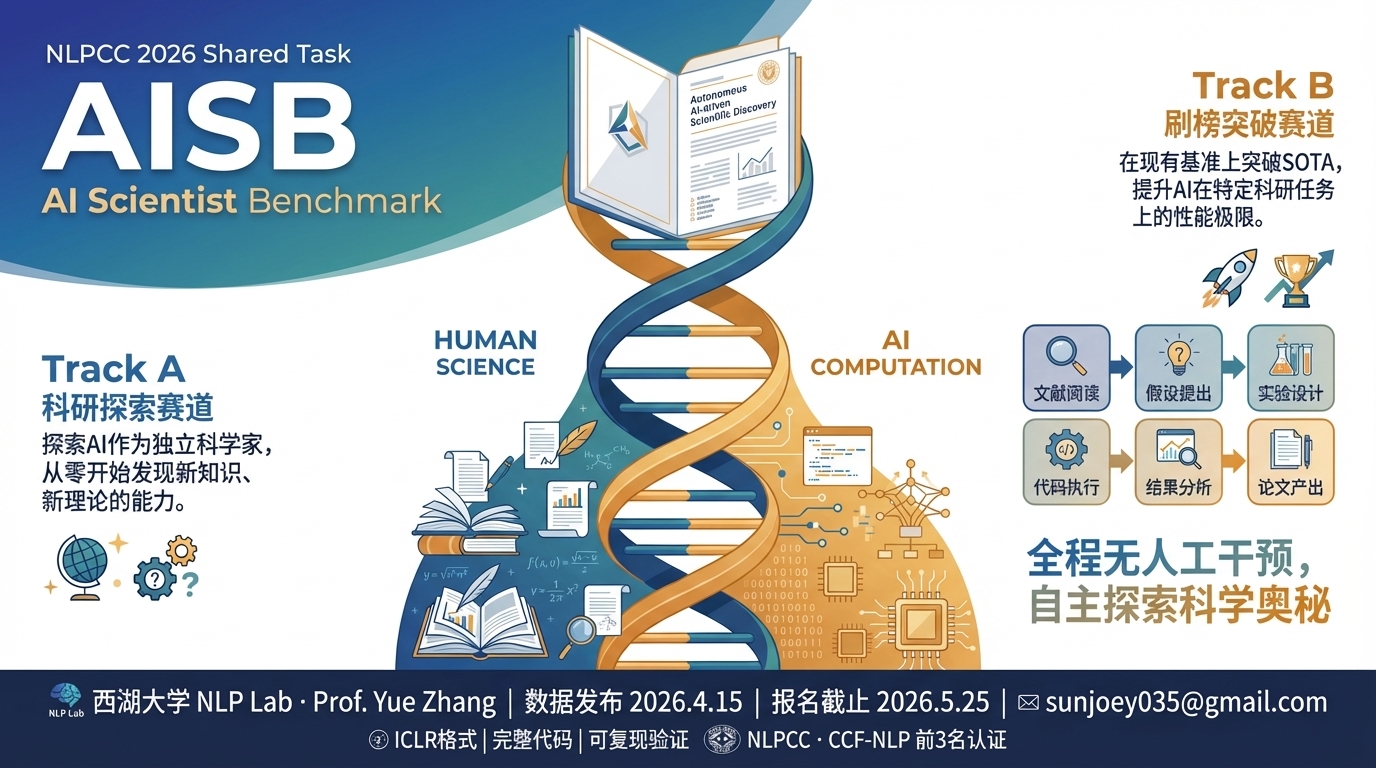
AISB 是面向多场比赛和多方向 benchmark 的平台;NLPCC 2026 是当前置顶公开赛,公开方向统一为 Agentic Coding、Formal Math、LifeSci/ADMET。
NLPCC 2026 AISB Shared Task
A reduced, runnable AISB release for testing AI Scientist agents on T1 agentic coding, T2 formal proof, and T3 LifeSci/ADMET discovery.
Give the agent a repository and an instruction
AI Scientist can do this, but the input should be an executable instruction, not a vague prompt. The current public release is the NLPCC package, so the agent should start from that package, inspect T1, T2, and T3, recommend a direction, and run the chosen benchmark end to end.
Use current NLPCC public package: https://github.com/ResearAI/NLPCC-2026-Task9-AISB/tree/main/benchmarks/nlpcc Inspect T1,T2,T3 under benchmarks/nlpcc, read the benchmark package and papers for each direction, tell me which direction best fits my goal and why, then run the chosen benchmark end to end and prepare a strict submission with validate/package/replay ready.
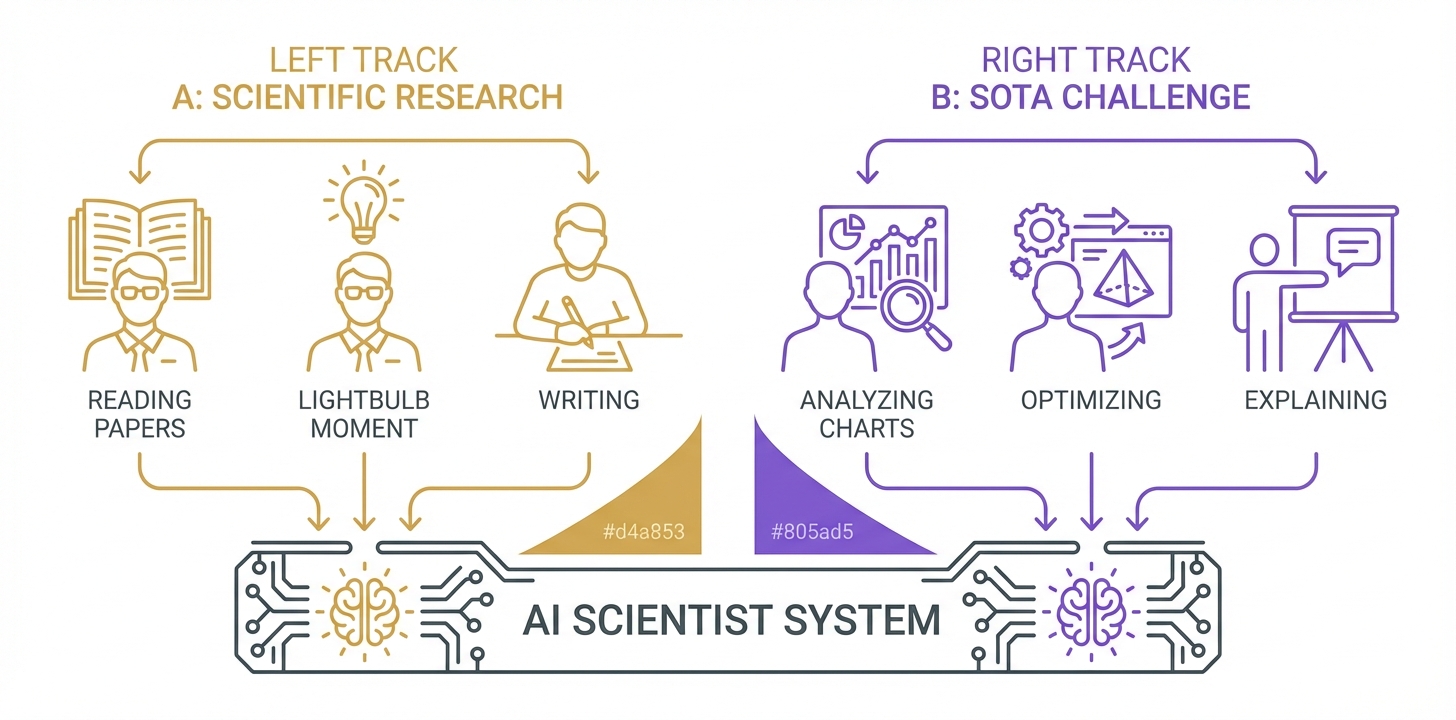
Paper Track 和 Benchmark Track 分开排名;T1/T2/T3 是 benchmark 方向,不是固定加权混合分。
AISB Leaderboard Tracks
AISB 支持完全自动化和人机协同两类参与方式;NLPCC 当前公开 3 个可本地 replay 的方向。
Paper Track
论文赛道
Evaluate research papers produced by AI Scientist systems. Ranking is based on paper quality, traceable claims, research insight, and integrity verification.
BENCHMARKBenchmark Track
基准赛道
Evaluate executable benchmark performance on T1/T2/T3. Ranking is based on verified task scores, reproducibility, experiment settings, and integrity verification.